Reading time: 10 min 30 sec
Table of contents
- MongoDB and AWS Lambda: a successful marriage?
- Why?
- Performance
- Cold start vs warm performance
- Performance conclusions
- VPC peering between AWS and MongoDB Atlas
- Useful links
MongoDB and AWS Lambda: a successful marriage?

Can we use MongoDB Atlas when working with AWS Lambda?
Yes we can!
It’s simple enough to setup and above all also performing well!
This blog concerns mainly two things:
- Why would you use MongoDB + AWS Lambda and how does it perform
- How to create a production grade setup with vpc-peering
Why?
As I am both a fan of AWS Lambda and MongoDB Atlas it was fun for me to marry them.
However in the real world we don’t do things for fun alone.

What are the motives to combine MongoDB Atlas and AWS Lambda?
- Combine the serverless capabilities of Lambda with the MongoDB strong points
- Payment model - In case of MongoDB you provision your cluster and you know what you’ll pay for it, clusters can grow with your business without downtime or code changes.
- Flexible Data Acces - MongoDB has a rich query language and aggregation framework. On top of your data in MongoDB you can build nice dashboards for business intelligence. (eg. MongoDB Charts)
- Indexes - Supports up to 64 indexes per collection with a wide variety of index types like hash, compound, unique, array, partial, TTL, geospatial, sparse, text and wildcard indexes
- Large documents allowed. A MongoDB document can be up to 16 Mb.
- Performance - a built-in cache and support for lots of secondary indexes that can span across arrays and subdocuments, making virtually all queries very fast
- Tunable consistency1
- Observability - MongoDB exposes more than 100 different metrics and has a built-in performance advisor. Because “you can’t optimize what you can’t measure.”
- Platform capabilities2
- Joinable documents 3
Performance
We are using AWS Lambda to store items in our MongoDB collection.
I want to measure the performance in two ways:
- Our Lambda Function has to setup a connection with the MongoDB cluster. Since we are using Lambda we have to deal with a cold start if the lambda has not been invoked shortly before. How is the cold start behavior when connections to the cluster have to be setup?
- When the Lambda has been invoked shortly before the connection is cached. How quickly does a save to the database happen when the Lambda Function is warm?
Suppose you have setup access from your Lambda Functions to your MongoDB Atlas Cluster (If you want to know how to do just that, read more about it in the second part of this post).
Since we are dealing with Lambda Functions we also have to deal with a phenomenon called “cold start”. This is the case for any Lambda Function no matter what database it connects to. MongoDB mentions on there website that there is an initial startup delay due to this.
I am testing using the following setup:

Items are coming in via requests through the API.
The APILambda drops the items on a queue.
A second Lambda Function SaveMongoDBLambda stores the items in the MongoDB database.
Of this second Lambda Function I will measure the performance:
- during a cold start
- when the Lambda is already warm
Other things important to know:
- In the above setup I limit the maximum number of concurrently running Lambda Functions instances of the
SaveMongoDBLambdato 10. - The Lambda Functions are written in
Javawhich will add time to the coldstart performance compared toPythonorNodeJS. - In this case I am reading the items from the queue one by one.
Also storing them one by one.
To optimize we would do this in batch.
Here we want to measure performance and we don’t want the batch size to vary. So we store them one by one. - The lambda function runs in a VPC to be able to make a peering connection to the MongoDB Atlas Cluster.
- The items that are being stored are only a few tens of bytes large.
- In total 1000 items were inserted
The results: analyzing the results using XRAY
I am using the AWS Xray SDK to trace and analyze the requests flowing through the application.
Here is a graph showing you the Response Distribution of the SaveMongoDBLambda.
Hence, this is the time that the Lambda Function took to execute.
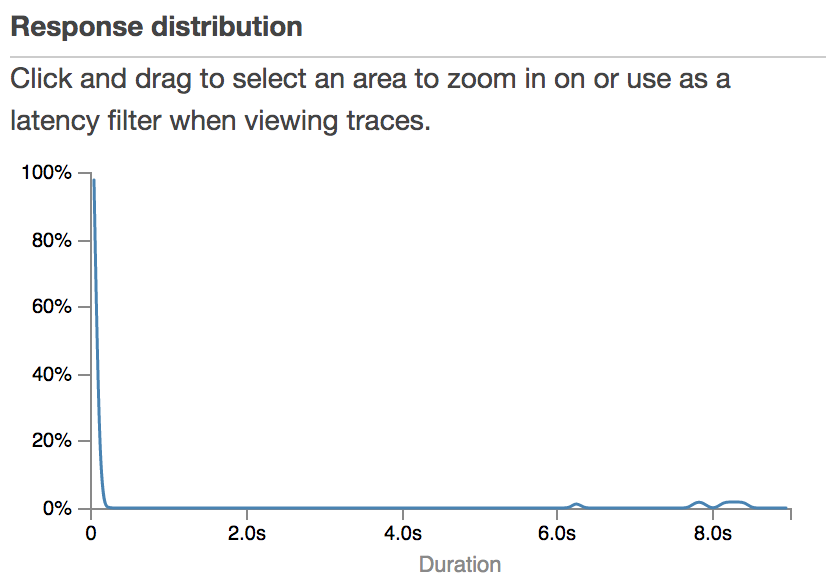
We notice two things.
- The graph is heavily balanced to the left. Most of the requests took very little time.
- On the right end of the spectrum we also see a couple of request. This are the cold starts that occur the first time a Lambda Function is invoked.
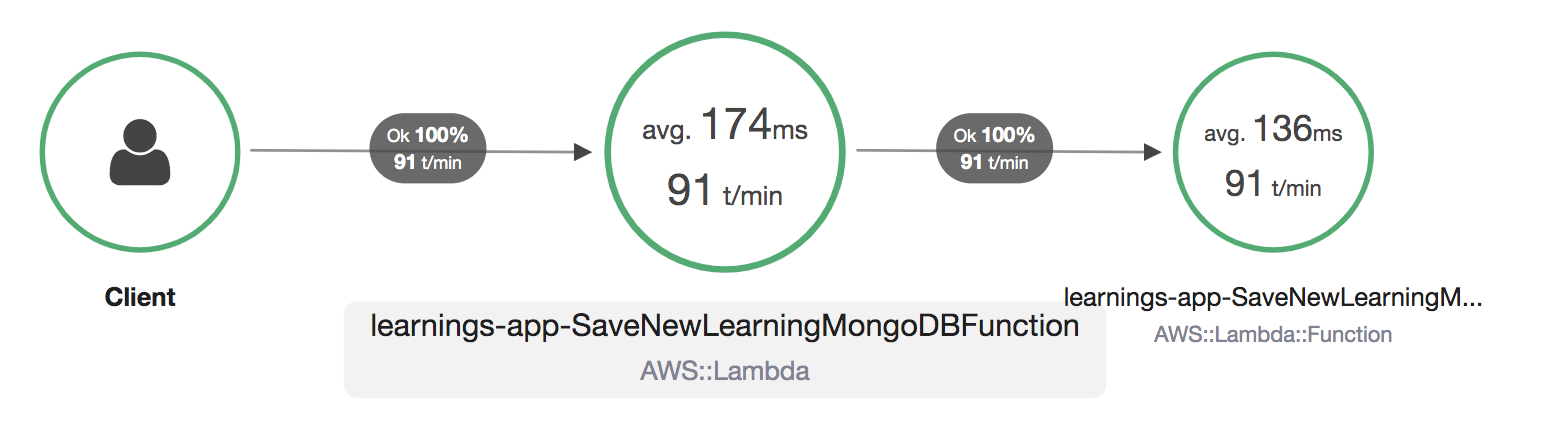
From the XRAY service map we can see that on average the Lambda Function took 174 milliseconds to execute.
Cold start vs warm performance
We can further dissect a cold start with XRAY.
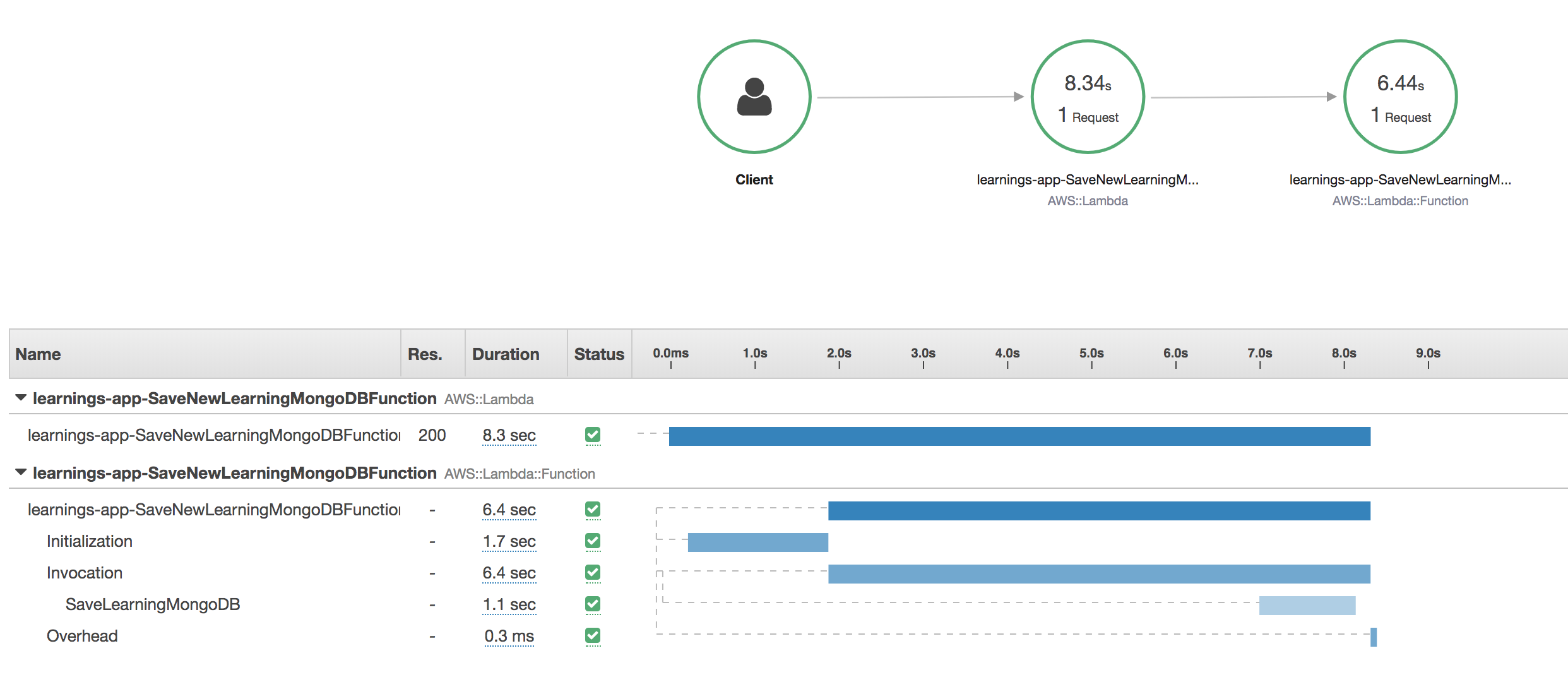
We see that:
- Bootstrapping the runtime and code in the vpc lambda took 1.7 seconds.
- The initial connection is being made to the database which takes 5 seconds. This connection overhead is also there when using AWS native databases. Though then it will be smaller.
- Saving the actual item took 1.1 second.
That’s for the first execution of the Lambda Function.
How does this compare against a Lambda function that is already “warm”.
This is how most invocations typically hit your Lambda Function.
This means the boostrapping is already done and the connections are initialised.
We can also analyse a warm lambda with XRAY.
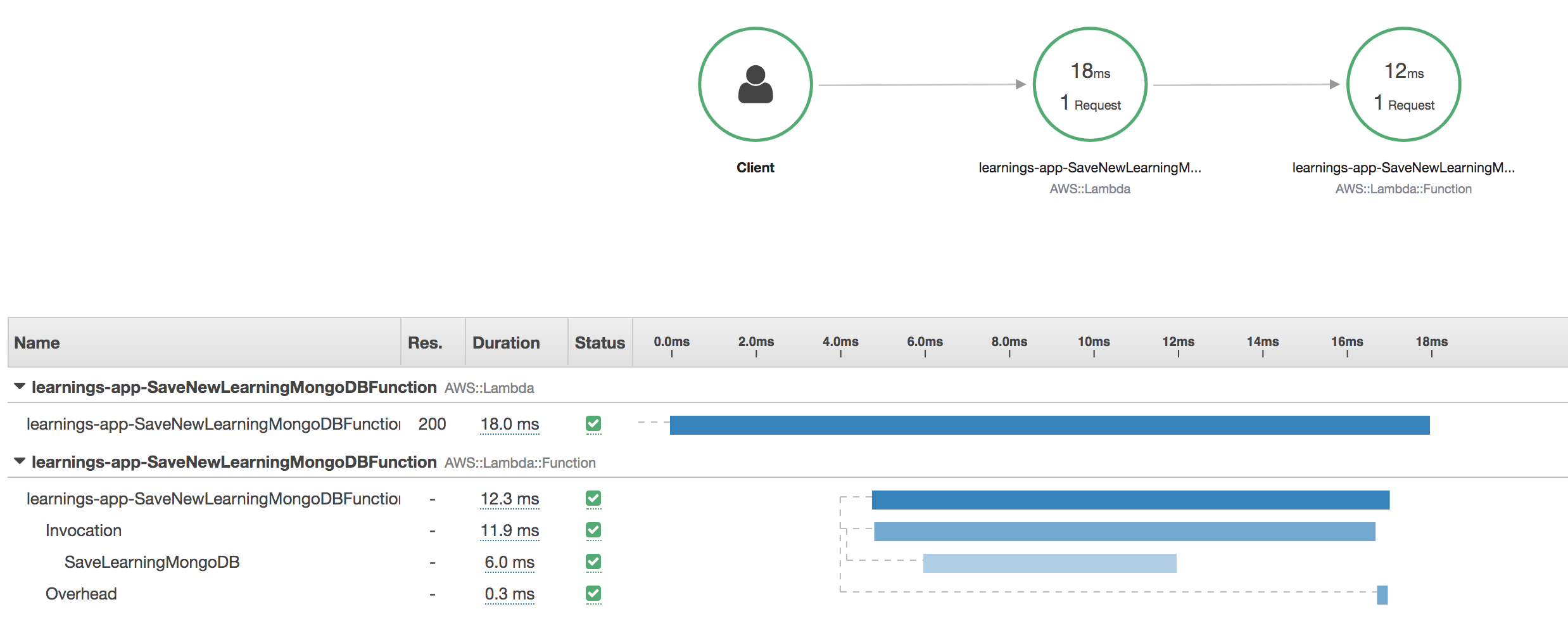
Now we notice:
- Total execution took only 18 ms!
- There is no longer any initialization overhead.
- Storing the item took 6 ms!
Performance conclusions
- Storing items in the database when the Lambda Function is already warm is blazingly fast.
- Initializing the connection in case of a cold start adds time to the cold start.
VPC peering: connect your Lambda Functions with your MongoDB Atlas Cluster
Want to know how to set up a VPC peering connection between your AWS VPC and MongoDB Atlas Cluster? Read on..
We want to deploy a production grade setup.
This means we won’t connect over the open internet.
We’ll setup a VPC peering connection between our Atlas Cluster and our AWS VPC.
The AWS side
Let’s setup a new VPC.
In this VPC we will create a public subnet.
A route table will be associated with that subnet.
In the route table we’ll define that we want to route all database traffic through the VPC peering connection towards the Atlas cluster.
In the AWS User Interface navigate to the VPC dashboard and click Launch VPC Wizard.

Select that you want to create a VPC with a single public subnet.
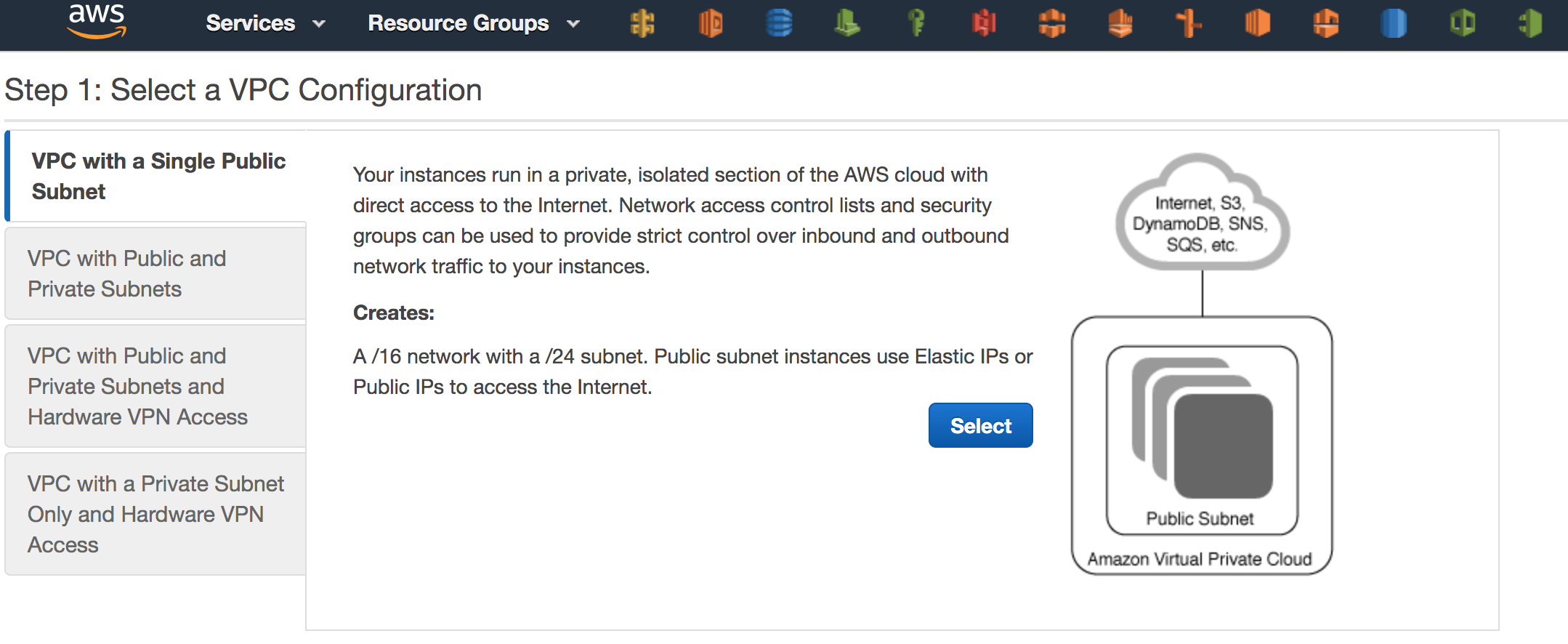
Specify how big you want the IP range of this VPC to be.
If you have trouble figuring out the relation between the CIDR block and the Network Range use one of the online converters to help you. (https://www.ipaddressguide.com/cidr) )
Give your VPC and public subnet a name.
Make sure that enable DNS hostnames is enabled.
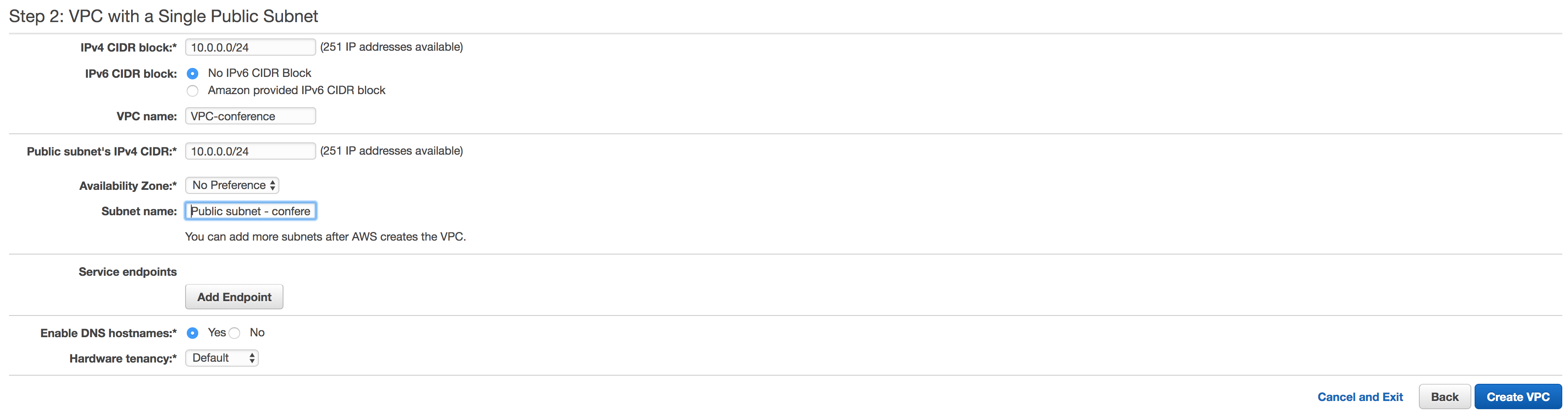
Your VPC has been successfully created.

If you now navigate to the subnet tab you see that a new subnet has been created.
When going to the route tables tab you see two new route tables.
That is a route table for your VPC and a route table specifically for your public subnet.


Before we go to MongoDB Atlas get some specific data about your VPC:
- From the subnet tab write down the VPC-id and IPv4 CIDR for the new subnet that was just created.
- Under the security group tab find the security group that is associated with your vpc. Write this security group identifier down.

The MongoDB side
Setup the MongoDB cluster. This has to be a dedicated cluster which means you’ll need at least an M10.

Wait till your cluster is set up.
In the Atlas UI navigate to Security -> Network Access.
Hit + new peering connection and select AWS as cloud provider.
The below screen will pop up. Here you have to specify some configuration.
- Account ID: your AWS account Id which you can find under the ‘My Account’ in the AWS console
- VPC-id: Fill in the VPC-id that you copied from the vpc that you just created in AWS
- VPC CIDR: specify the CIDR block that you used to configure your vpc with on AWS
- region: the region where you created the AWS vpc
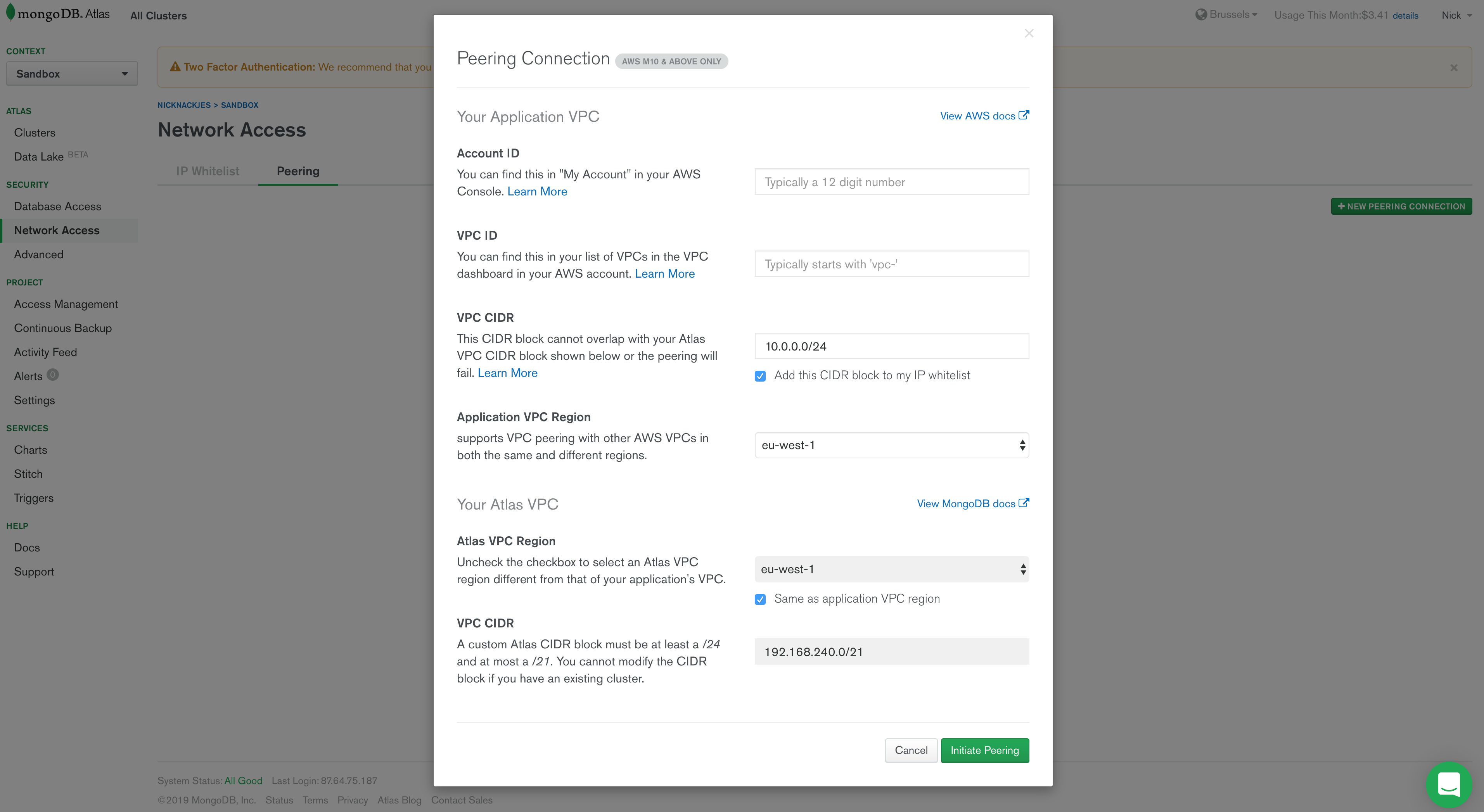
Hit Instantiate peering !

Notice that MongoDB created an Atlas CIDR which specifies the IP range in which your Atlas cluster will reside. Write this down, you will need it later on.
We are connecting the Atlas IP range with the IP range of our AWS VPC, hence VPC peering.
The peering connection is now pending.
Go back to AWS.
The AWS side (again)
In the VPC service of AWS go to Peering Connections.
You will notice a new peering request with status Pending Acceptance.
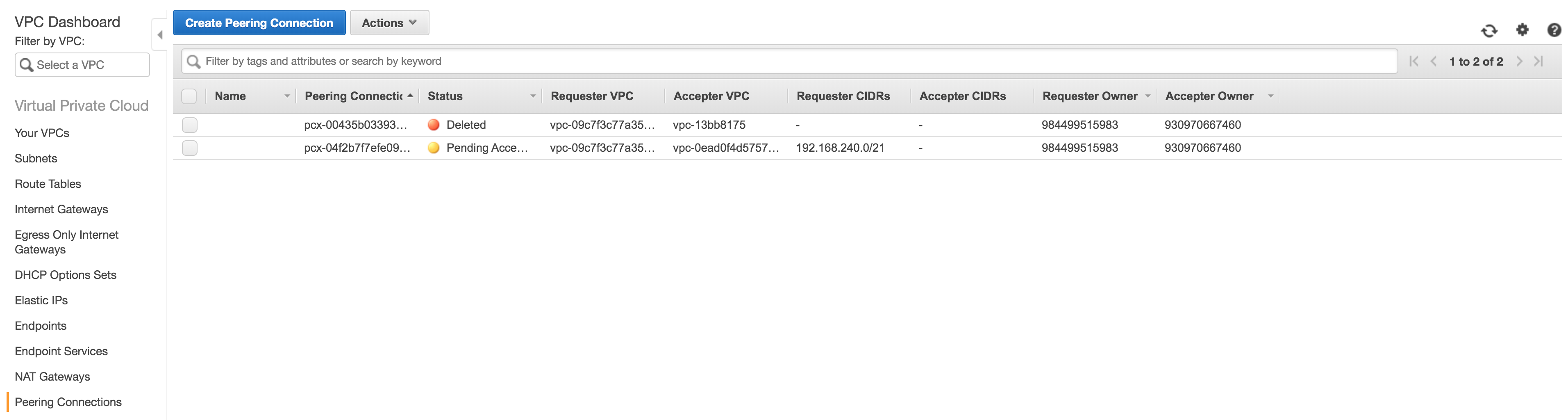
Accept this peering request!
Now you have to update your routing tables.
AWS will also ask you Do you want to update your routing tables when you accept the peering request. Click Modify my route tables now.
We will deploy our Lambda Functions in the public subnet of our VPC.
So we want to modify the route table that is associated with that subnet.
You can recognize that route table because it has an explicit subnet association.

Selecting the route table with an explicit subnet association and click edit routes.
Add a route towards your Atlas cluster as indicated in the image below.
What we are actually saying here is that we want to route all traffic to our Atlas cluster through the VPC peering connection.
As Destination choose the Atlas CIDR and under Target choose your VPC peering connection.
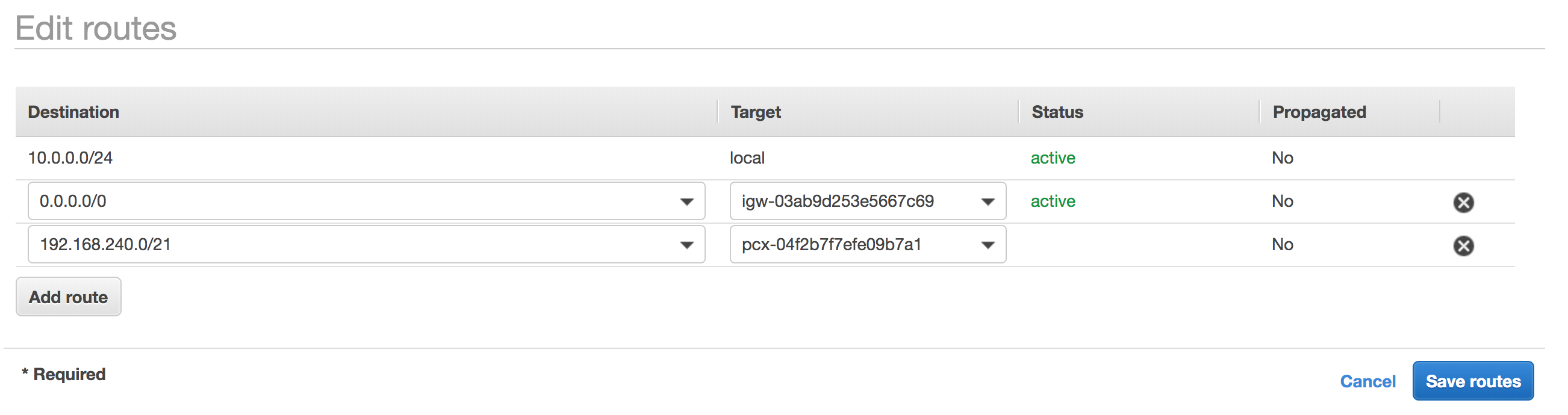
Updating the route table will update the status of the peering connection to available in the Atlas UI.
This takes a couple of minutes.

Deploy your lambda functions!
Now it is time to deploy your Lambda Function in the VPC that you just configured. This Lambda Function will connect to your MongoDB Atlas Cluster via the vpc-peering we have set up.
I created a project that you can use to deploy a Lambda Function in your own vpc.
You can then use it to store items in your MongoDB collection.
The repository can be found here.
Let me be clear and state that in a real world project you don’t want the password hard coded in the connection string.
An option is to put it into AWS Secret Manager and have your lambda retrieve it there.
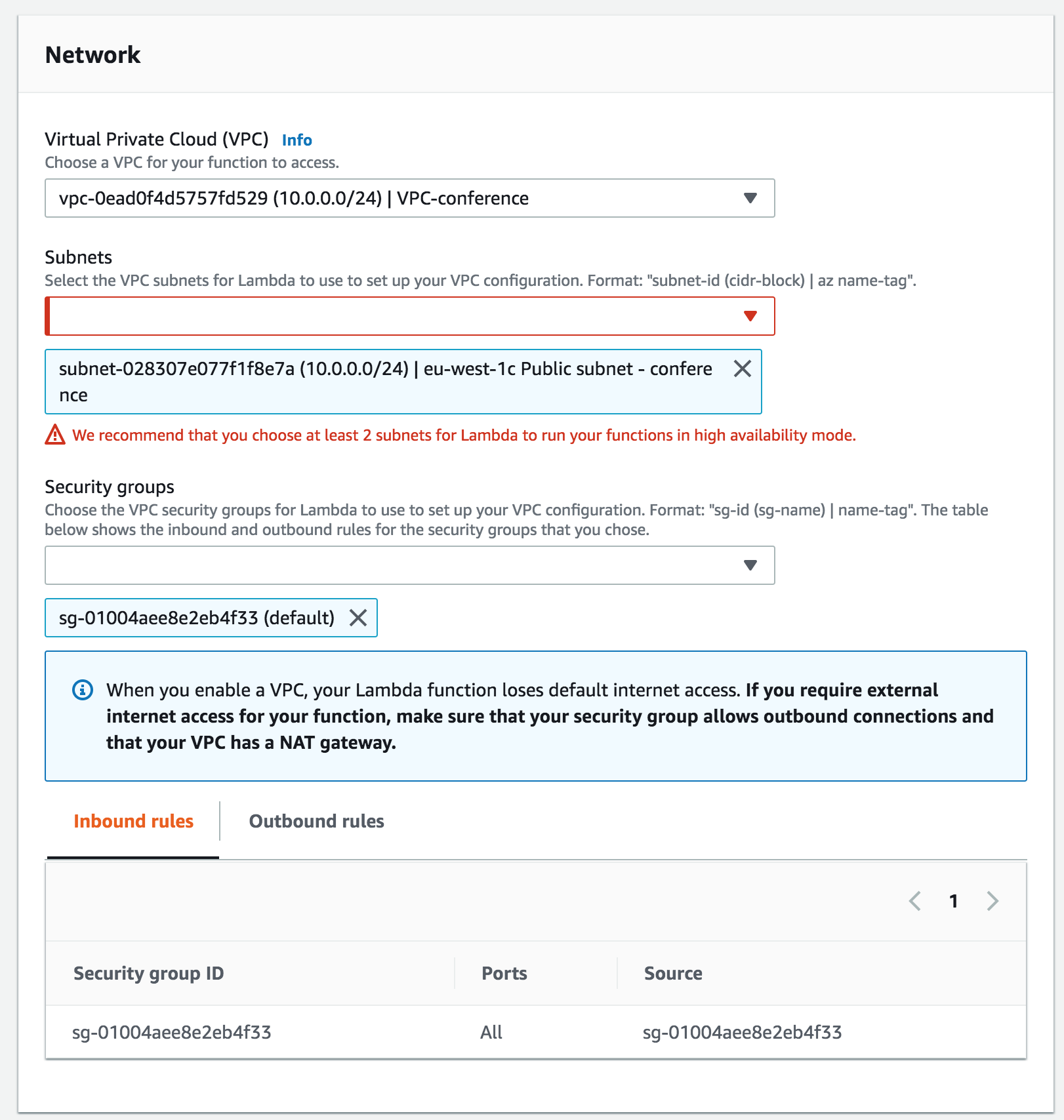
You need to update certain config values in this project to make it work for your own vpc! To deploy a Lambda Function in your VPC you have to configure the VPC config:
- use the pubic subnet that we just created
- specify the security group of you AWS vpc You also have to update the connection string.
The following instructions can also be found in the README of the project.
In template.yaml:
- update the environment variable that specifies the connection string, database and collection to your own connection string, database and connection.
Environment: Variables: MONGODB_CONNECTION_STRING: mongodb+srv://<user>:<password>@<your-cluster>.mongodb.net/test?retryWrites=true&w=majority DATABASE: yourDatabaseName COLLECTION: yourCollectionName - update the
VpcConfigwith your own vpc security group and subnet:VpcConfig: SecurityGroupIds: - sg-01004aee8e2eb4f33 SubnetIds: - subnet-028397e077f1f8e7a
Deploy your Lambda functions to your VPC and test them out!
Run ./deploy.sh to deploy the Lambda Function to your account.
Running this script successfully will output the URL on which you can send an item through the API towards the Lambda Function.

In the Lambda User Interface of the AWS Console you will now see that the Lambda Function has been deployed in the correct subnet with the right security group.
Use this URL that was outputted to trigger the Lambda Function.
This will return the ObjectId of the item in your MongoDB collection!
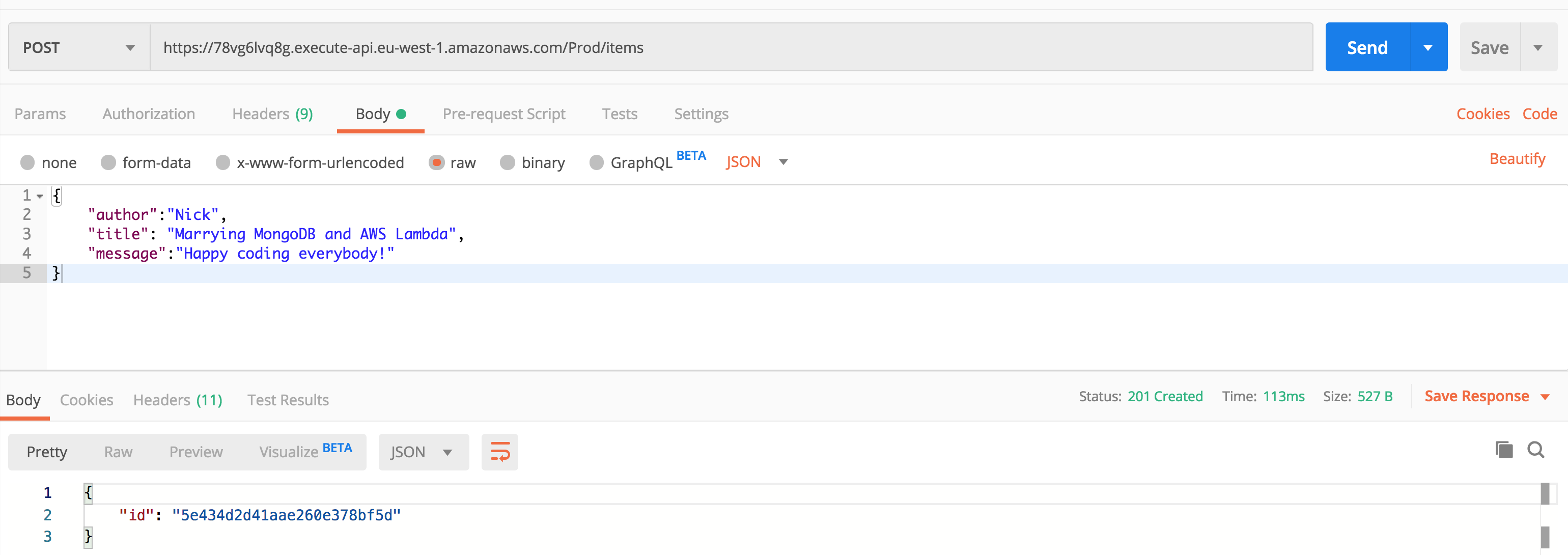
Yihaa! MongoDB and AWS Lambda are happily married!
Useful links
- https://docs.atlas.mongodb.com/security-vpc-peering/
- https://aws.amazon.com/xray/
- https://www.mongodb.com/compare/mongodb-dynamodb
- https://www.educba.com/mongodb-vs-dynamodb/
- https://www.mongodb.com/blog/post/optimizing-aws-lambda-performance-with-mongodb-atlas-and-nodejs
Footnotes
Operations can be grouped in full ACID-compliant transactions at any scale. In any case, indexes are always kept in sync in realtime with the data so your users will always find and work with the latest, correct data.
-
Tunable consistency: a variety of consistency levels allowing client applications to select the trade-offs they want to make when it comes to the strongest consistency or the lowest latency. ↩
-
Platform capabilities such as Full Text Search with Lucene, Stitch Serverless Platform with GraphQL support, Charts, managed triggers, more than 30 programming language drivers, Data Lake, analytics, Kafka 2-way connector ↩
-
Joining documents: when rich documents that are loosely coupled (users and invoices for instance) need to be queried, MongoDB can join documents together inside the database, making your code more light. ↩



